✆ + 1-646-235-9076 ⏱ Mon - Fri: 24h/day
Predictive Maintenance: A Technical Deep Dive (Part 2)

In the first part of this series, we explored predictive maintenance (PdM) from a strategic perspective. Now, it’s time to get under the hood and examine the technical components that make this concept a reality. This article is dedicated to the technologies, algorithms, and processes that form the core of modern predictive maintenance systems.
The Predictive Maintenance Technology Stack
A modern PdM system is a complex, multi-layered architecture where each component plays a critical role. The success of the entire system depends on the seamless operation of all its parts, from the physical sensors on the factory floor to the cloud-based analytics platforms.
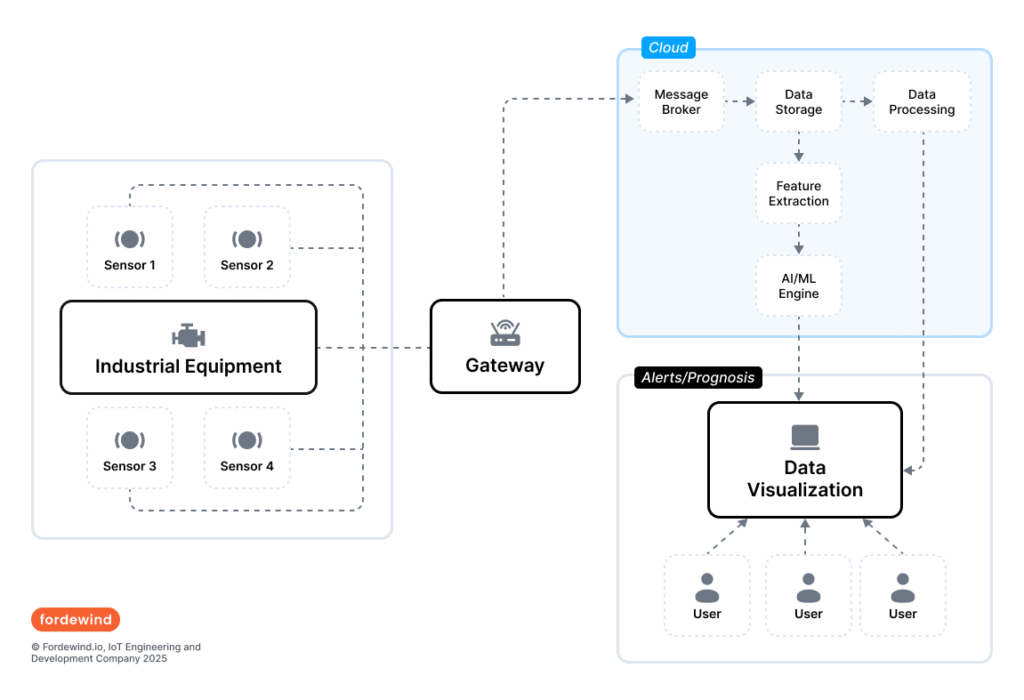
Data Collection: Industrial IoT (IIoT) and Sensor Technologies
The entire PdM system is built on a foundation of data. Industrial Internet of Things (IIoT) sensors are the “nervous system” of this architecture, continuously collecting real-time data on the condition and performance of equipment. The choice of specific sensors depends on the type of asset and the failure modes being monitored.
It is crucial to understand that the PdM technology stack is a tightly integrated ecosystem. The quality of each layer directly impacts the effectiveness of the next. Using low-quality sensors or placing them incorrectly will generate “garbage” data. This poor-quality data will then be transmitted and stored, consuming valuable resources. Ultimately, even the most sophisticated machine learning models, when trained on garbage, will produce inaccurate and unreliable predictions, leading to a loss of trust from technical teams and devaluing the entire investment.
Table 1: Application of Sensors for Fault Diagnosis
| Sensor Type | Monitored Parameter | Typical Applications | Detectable Faults |
| Vibration (Accelerometer) | Acceleration, velocity | Motors, pumps, gearboxes, bearings | Imbalance, misalignment, looseness, bearing wear |
| Thermal (Infrared) | Surface temperature | Electrical cabinets, motors, bearings | Overheating, poor lubrication, electrical faults |
| Acoustic (Ultrasonic) | High-frequency sound waves | Compressed air leaks, bearings | Early-stage bearing failure, gas leaks |
| Electrical (Current Analysis) | Current, voltage | Electric motors, transformers | Rotor breakage, winding faults |
| Pressure Sensor | Fluid/gas pressure | Pipelines, hydraulic systems | Leaks, blockages, cavitation |
Data Transmission and Storage: The Role of Cloud and On-Premise Solutions
Once collected, data from the sensors must be transmitted to a central location for storage and analysis. This can be done over wired or wireless networks.
- Cloud Computing: Cloud platforms like Microsoft Azure or Amazon Web Services are the cornerstone of modern PdM systems. They offer scalable resources for storing and processing the vast amounts of data generated by sensors.
- On-Premise Deployment: For organizations with strict data sovereignty requirements or in environments with limited connectivity, solutions can be deployed locally.
- Hybrid Models: A combination of cloud and on-premise solutions is often used, incorporating Edge Computing to pre-process data before sending aggregated information to the cloud.
The Analytics Engine: AI, Machine Learning, and SCADA Integration
Raw sensor data is meaningless without analysis. This is where artificial intelligence (AI) and machine learning (ML) come into play. ML algorithms are the “brain” of the PdM system, analyzing data to identify patterns and make predictions.
PdM systems must be integrated with existing industrial control systems:
- SCADA (Supervisory Control and Data Acquisition): PdM models can be integrated with SCADA systems to display predictions and alerts directly in the operator’s interface.
- ERP (Enterprise Resource Planning) and CMMS (Computerized Maintenance Management System): Integration with these systems creates a closed-loop management cycle. When a failure is predicted, the system can automatically generate a work order in the CMMS and initiate a parts order in the ERP.
Machine Learning as the Core of Predictive Analysis
Machine learning (ML) is the engine that drives predictive maintenance, turning streams of raw sensor data into actionable forecasts.
Key Machine Learning Tasks in PdM
The goal of ML in PdM is to answer critical questions about equipment health. These questions can be grouped into three main categories, representing levels of predictive analytics maturity:
- Anomaly Detection: “Is this asset behaving differently than usual?” This is the first and most fundamental step. Algorithms identify deviations from normal operating parameters.
- Fault Classification: “Is there a fault, and what type is it?” After detecting an anomaly, classification models can diagnose the specific type of fault (e.g., “bearing wear” versus “shaft misalignment”).
- Remaining Useful Life (RUL) Estimation: “When is this component likely to fail?” This is the most complex and valuable task. Regression models predict a continuous value, such as the number of days or operating cycles left before an expected failure.
Overview of Key Algorithms and Model Families
A wide range of supervised and unsupervised learning methods are used in PdM. The choice of algorithm depends on the specific task, data type, and required accuracy.
Table 2: Machine Learning Algorithms for Predictive Maintenance Tasks
| PdM Task | Problem Type | Common Algorithms | Key Advantages |
| Anomaly Detection | Unsupervised Learning | Autoencoders, Clustering | Well-suited for unlabeled data, finds novel issues |
| Fault Classification | Supervised Classification | Random Forest, SVM, XGBoost | High diagnostic accuracy, interpretability (Random Forest) |
| RUL Prediction | Supervised Regression (Time-Series) | Linear Regression, LSTM | Excellent for time-series data, captures degradation trends |
The success of PdM is not determined by model complexity alone. The most successful initiatives are implemented by interdisciplinary teams where maintenance engineers, data scientists, and IT specialists collaborate closely. An experienced engineer knows the causes of failure, but without quality data, their expertise cannot be converted into a model. Conversely, a data scientist can create a technically perfect model, but without understanding the physics of the machine, they won’t know which sensor signals are truly important.
The Data Scientist’s Workflow
Creating a predictive model is a structured process :
- Data Collection and Loading: Gathering historical operational data, maintenance logs, and real-time sensor data. It is crucial to have data on both normal operations and failure instances.
- Data Pre-processing and Cleaning: A critical step that includes handling missing values, removing outliers, and correcting inconsistencies.
- Feature Engineering and Selection: Identifying the most relevant data characteristics (features) that correlate with failures to improve model performance.
- Model Training and Validation: The model is “trained” on historical data to learn patterns and then “tested” on unseen data to evaluate its accuracy.
- Deployment and Monitoring: The model is deployed in a production environment and continuously monitored, periodically retraining on new data to maintain accuracy.
The Future of Predictive Maintenance: New Horizons
Predictive maintenance continues to evolve rapidly. Advanced technologies promise to make PdM even more powerful, autonomous, transparent, and secure.
Digital Twins: The Virtual Proving Ground
A digital twin is a dynamic virtual replica of a physical asset, continuously updated with real-world data. In the context of PdM, digital twins provide a powerful environment for simulation. Engineers can run “what-if” scenarios to test the impact of different operating conditions in a safe, virtual space. This enables a shift from predictive to
prescriptive maintenance, where the system not only predicts a failure but also recommends optimal corrective actions.
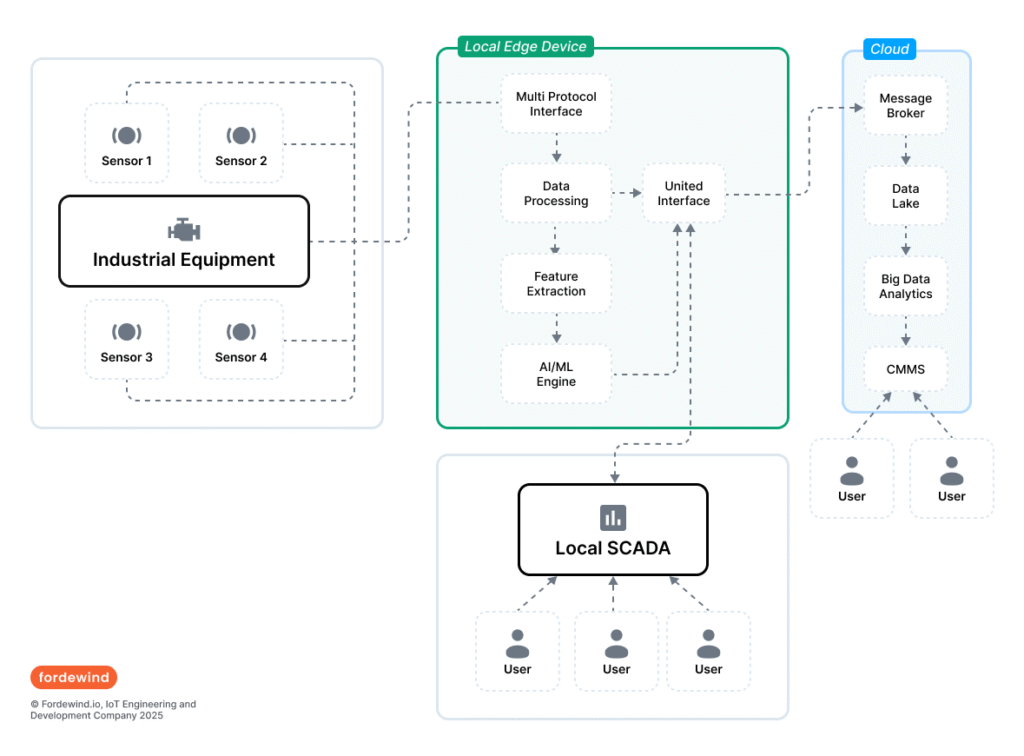
Edge Computing: Intelligence at the Source
Edge computing is a paradigm where data processing occurs locally, on or near the device (“at the edge” of the network), instead of sending all data to a centralized cloud.25 For PdM, this offers several key advantages:
- Reduced Latency: For applications requiring instant decisions, edge processing eliminates the delay of a round trip to the cloud.
- Bandwidth Efficiency: Only important insights are sent to the cloud, significantly reducing network load.
- Enhanced Security and Privacy: Sensitive data is processed locally, minimizing its vulnerability.
- Autonomous Operation: Edge devices can continue to operate even if cloud connectivity is lost.
Explainable AI (XAI): Opening the “Black Box”
A major barrier to the adoption of complex ML models is their “black box” nature. They can make accurate predictions, but it’s often impossible to understand why a decision was made. Explainable AI (XAI) is an emerging field aimed at making AI decisions understandable to humans. In PdM, this means explaining with a prediction (e.g., “Failure is likely because vibration at frequency X increased by 15%”). This transparency helps build trust with maintenance teams.
Federated Learning: Collaborative Intelligence with Privacy Preservation
Training highly accurate models requires vast datasets. However, organizations are often unwilling to share their sensitive operational data. Federated Learning (FL) solves this dilemma. It’s a decentralized approach where a global model is sent to multiple devices (e.g., different factories). Each device trains the model locally on its own data without sharing it. Only the updated model parameters are sent back to a central server to improve the global model. FL allows multiple organizations to collaboratively build a more robust model without exposing confidential information. The combined application of these technologies paves the way for a new paradigm: moving from today’s predictive systems to tomorrow’s prescriptive and, ultimately, autonomous systems capable of self-diagnosis and self-repair. Find Part 1 here.