✆ + 1-646-235-9076 ⏱ Mon - Fri: 24h/day
How Cloud-Native Thinking Transforms Traditional Industries

For decades, if you heard an “infrastructure” word, you would immediately think about something heavy, physical, like racks, cables, blinking LEDs, and cold-as-hell air-conditioned rooms guarded like treasure vaults. Right now, in many cases, infrastructure looks more like software. The cloud has changed how entire industries think about reliability and cost.
We can say that Cloud-native thinking is a philosophy of designing systems that adapt, scale, and evolve instead of rusting in place. And for many traditional industries, that change has been nothing short of revolutionary.
Data Centers, On-Premise, and the Cloud: What’s the Difference?
Before we talk about transformation, we need to clarify the playing field.
On-Premise
In an on-premise setup, every piece of infrastructure, from servers to network cables, is owned and maintained by the company’s engineers.
It offers full control but also full responsibility: hardware failures, security, power, and cooling all fall on your shoulders. When something breaks, your team fixes it — even at 3 a.m.
Data Centers (Colocation)
Data centers were the first step toward outsourcing. Companies rent space in a professional facility, using its power, cooling, and security while keeping control over their own hardware. It’s less stressful than on-prem, but scaling still means buying and installing new physical servers.
Cloud
The cloud eliminates the physical layer. You no longer buy machines; you rent capabilities: compute, storage, networking, that can expand or shrink automatically.
Providers such as AWS, Azure, and Google Cloud deliver near-instant scalability, global reach, and managed reliability, freeing businesses to focus on their core products instead of their infrastructure plumbing.
How Infrastructure Looked in the 2000s
In the early 2000s, infrastructure meant server rooms and sysadmins in thick jumpers. Cloud computing was barely emerging, and virtualization was still new.
A Typical 2000-Era Setup
- Physical servers for every application
- Manual updates and backups
- Separate environments for testing and production often on the same hardware
- Limited redundancy; one broken disk could take hours to replace
- Scaling = ordering new servers (delivery in 2–4 weeks)
- Uptime measured by luck, not automation
The concept of “infrastructure as code” or “serverless” didn’t exist in popular meaning.
If traffic spiked, websites went down, and recovery meant someone literally running into a cold room with a screwdriver.
That was acceptable then, but impossible now. Modern users expect near-instant responses, and downtime can destroy reputations in minutes. Just imagine a banking app that doesn’t respond to an attempt for authentication, especially if you’re in line or at a gas station and you need to pay. Not cool, not cool at all.
Why the Cloud Is a Better Option and When It’s Not
The rise of cloud-native platforms flipped the model upside down. Instead of planning years ahead, businesses now scale minute by minute. But cloud isn’t automatically the best choice for every use case.
Why Cloud Wins
- Global Reach – Deploy your product in North America, Europe, and Asia within minutes.
- High Availability – Built-in multi-region redundancy ensures continuity.
- Elastic Scaling – Automatically handle seasonal demand or marketing spikes.
- Serverless and Managed Services – Focus on business logic, not hardware maintenance.
- Security and Compliance – Cloud providers maintain strong physical and logical safeguards.
- Innovation Speed – New services can be integrated within days instead of months.
When your product serves a worldwide audience, think streaming platforms, fintech systems, or healthcare IoT cloud – the cloud probably will be the best choice.
When On-Premise or Data Centers Make Sense
Some workloads don’t need the flexibility or cost of cloud scaling. If you run a local car repair shop in Dallas, your app doesn’t need global replication, low-latency routing, or six-nines uptime. A single well-managed dedicated server or a small datacenter rack might be cheaper and easier to maintain.
In short: scale your architecture to your business reality.
Use the cloud when agility, global presence, or high reliability matter, and stay local when simplicity is king.
The Price of Reliability and The Real Cost of “Nines”
Reliability sounds simple until you start paying for it.
Every extra “nine” of uptime represents exponentially higher complexity and cost.
| Availability | Downtime per Year | Relative Cost |
| 99% | ~3.65 days | baseline |
| 99.9% (three nines) | ~8.7 hours | × 2–3 |
| 99.99% (four nines) | ~52 minutes | × 5–10 |
| 99.999% (five nines) | ~5 minutes | × 15–20 |
| 99.9999% (six nines) | ~30 seconds | × 30+ |
Each additional “nine” requires redundant systems, backup regions, instant failover, multi-zone databases, real-time replication, and round-the-clock staff.
If your business absolutely depends on 24/7 uptime, such as stock exchanges, hospitals, or payment systems, the cloud is the only realistic solution.
Building equivalent resilience on-premises would mean owning multiple geographically separated data centers, redundant power sources, and a 24/7 operations team.
In contrast, cloud providers already have all that infrastructure ready. That’s why industries that need “five nines” of uptime are now fully cloud-based or hybrid; it’s simply not economical to do otherwise.
For everyone else, aiming for 99.9%–99.99% uptime offers an ideal trade-off between cost and reliability.
Example of a Proven Flexible Architecture on AWS
Here’s what a modern, multi-region, auto-scaled, low-latency AWS architecture looks like — one that embodies true cloud-native thinking.
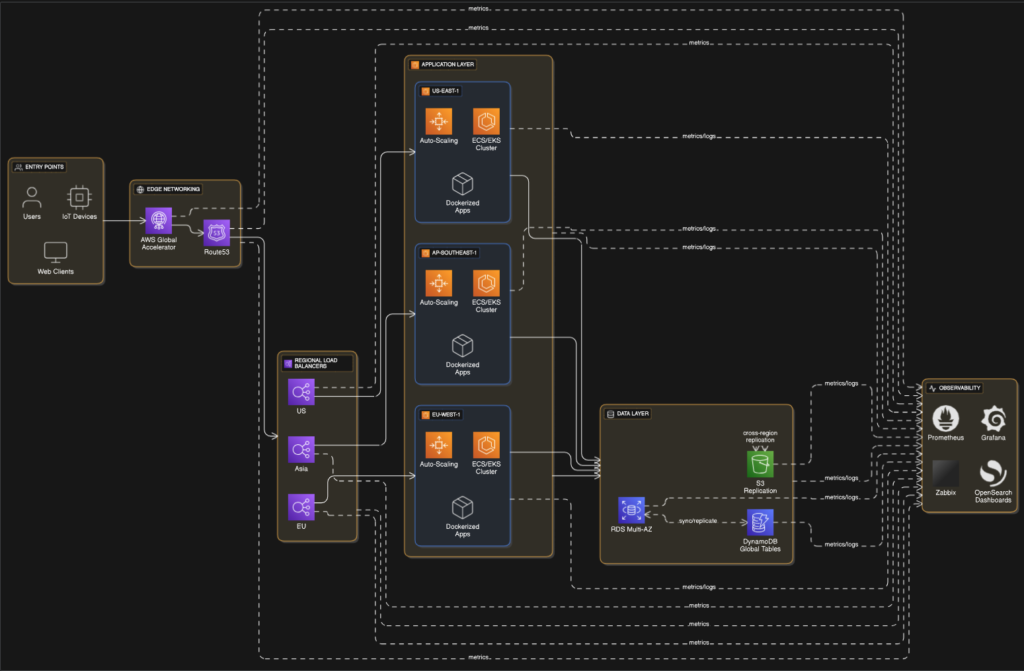
Why This Is Effective
- Low Latency – Data is served from the closest region.
- High Availability – Automatic failover between continents.
- Autoscaling – Adjusts to demand in seconds instead of hours.
- Flexibility – Components can be replaced or migrated without downtime.
- Portability – Works with similar setups on Azure, GCP, or private cloud.
If your organization demands four nines or more, this architecture delivers it at a fraction of what it would cost to build equivalent resilience on physical hardware.
How Fordewind.io Helps Companies Move to Cloud-Native Success
At Fordewind.io, we help organizations make this leap from static infrastructure to adaptive, cloud-native ecosystems.
Our Expertise:
- Cloud and Hybrid Design — Combine AWS with private datacenters or edge nodes.
- Cost Optimization — Identify and reduce hidden cloud expenses.
- Resilient Architectures — Build multi-region, high-availability systems with realistic uptime goals.
- IoT and Data Integration — Connect global fleets of sensors, vehicles, and smart devices.
- End-to-End Delivery — From proof-of-concept to production rollout.
- Cross-Industry Experience — Healthcare, finance, e-commerce, EV chargers, smart homes, and industrial automation.
Our mission is to help clients use cloud intelligently, leveraging the elasticity of modern platforms without overpaying for what they don’t need.
Conclusion
Where 2000-era companies bought servers and hoped for stability, modern organizations deploy architectures that adapt in real time. You just can’t ignore that.
Cloud-native thinking teaches us that scalability, observability, and automation are true business enablers. But every decision carries a cost. Each extra “nine” of uptime demands careful justification. The best companies today use cloud logic: flexible, global, efficient, and focused on outcomes, not hardware.
At Fordewind.io, we help you reach that level whether you’re a startup building your first product or an enterprise re-architecting for the next decade.
Because in the cloud era, survival belongs to those who scale smart.